Python Function read excel / csv files from a given directory and its subdirectories
Code¶
The code for the function is as shown below:
Explanation¶
-
The function
extract_datatakes in the following parameters:- directory_path: the path to the directory to search for Excel and CSV files
- columns_to_extract: a list of column names to extract from each file
- date_columns: a list of column names to parse as dates using pd.to_datetime()
- rows_to_skip: the number of rows to skip when reading each file
- output_filename: the path and filename to save the extracted data in a CSV file
-
The function starts by creating an empty DataFrame called
extracted_data. -
It also initializes variables
files_with_no_columnsandsheet_readto track files that do not contain the specified columns and to keep track of the current sheet being read when extracting data from Excel files. -
The list
extracted_columnsis created by copying the inputcolumns_to_extractlist and adding additional columns for thefilename,subdirectory name,file creation date, andlast modified date. -
The function then loops through all the files in the specified directory and its subdirectories using os.walk().
-
For each file, it checks if it has a ".xlsx", ".xls", or ".csv" extension.
-
If the file is a CSV file, the function reads it into a DataFrame using
pd.read_csv(), skipping the number of rows specified byrows_to_skip. -
It then checks if all the columns in
columns_to_extractare present in the DataFrame. If so, it setscolumns_found_outertoTrueand proceeds to the next step. If not, it setscolumns_found_outertoFalseand moves on to the next file. -
If the file is an Excel file, the function reads all sheets in the file into a dictionary of DataFrames using
pd.read_excel()andsheet_name=None. It then loops through all the sheets and all the columns incolumns_to_extract, checking if each column is present in each sheet's DataFrame. If all the columns are present in a sheet, it setscolumns_foundtoTrueand proceeds to the next step. If not, it setscolumns_foundtoFalseand moves on to the next sheet in the same Excel file. If at least one sheet contains all the specified columns, the function combines the DataFrames of all sheets into one usingpd.concat(). -
If
columns_found_outerisTrue, it extracts thefilename,subdirectory name,file creation date, andlast modified dateusingos.path.basename(),os.path.getctime(), andos.path.getmtime(), and adds them as new columns to the DataFrame. It then appends the DataFrame to theextracted_dataDataFrame. -
If
columns_found_outerisFalse, it increments thefiles_with_no_columnscounter and prints a warning message. -
Finally, the function checks if any files contained the specified columns. If not, it returns None. Otherwise, it sorts the
extracted_dataDataFrame by filename and saves it to a CSV file usingto_csv(). It then prints the number of files processed, the number of files that did not contain the specified columns, and the path to the output file.
Sample Usage¶
The function can be called in python as shown below:
# set directory path
directory_path = './Work' # Path for the directory where all the files containing data for extraction are to be searched
# set the columns you want to extract
columns_to_extract = ['Region','Country', 'Product Number','Quantity','Date of Sale']
date_col = ['Date of Sale']
# set the rows to skip
skiprows = 0 #this basically will be number of rows in begining of the files which must be skipped to reach the header row of the data
output_filename = 'Regional Sales Data.csv'
#Call function
df = extract_data(directory_path,columns_to_extract,date_col,skiprows,output_filename)
Now, assuming there were 12 separate files for past 12 months inside the folder then so long as all those files, irrespective of whether they are csv or excel, have the columns Region,Country, Product Number,Quantity,Date of Sale; the function will read the files and extract the data and return it to the dataframe df.
GUI Implementation¶
A very basic GUI implementation of above function using PySimpleGUI with all code is available here
Usage¶
The script can directly be copied to a Jupyter cell or can be run from terminal. Following command should ensure all dependencies are installed:
Some things the GUI takes care of are:
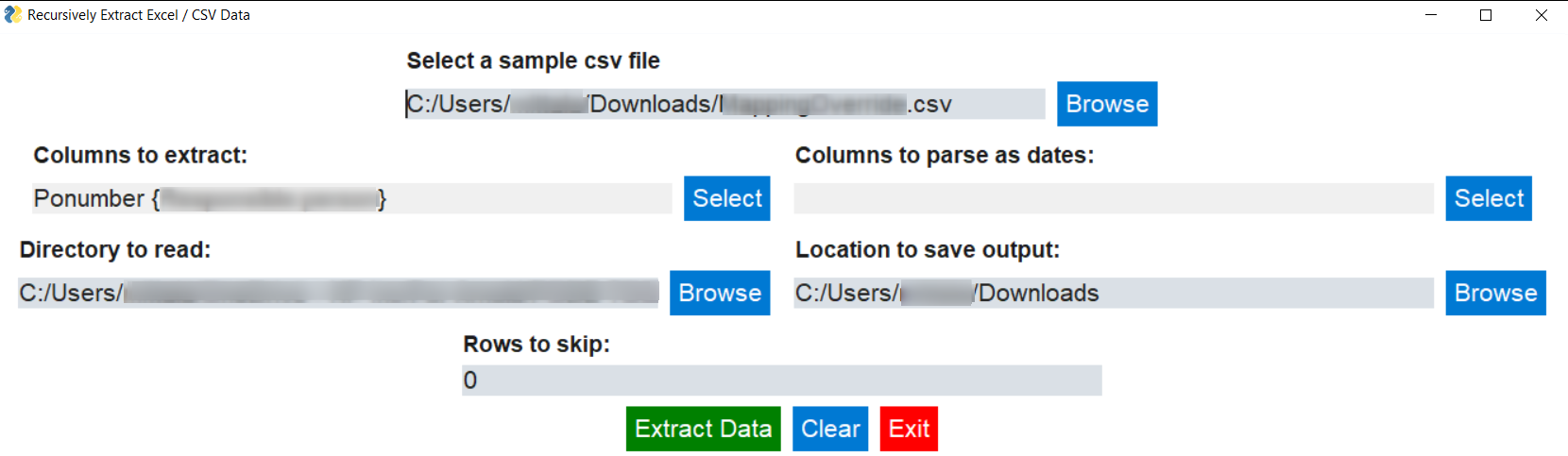
- Allows selection of columns to be extracted from a sample
.csvfile - Allows user to specify which of the selected columns should be parsed as
date - Gives a date based filename to
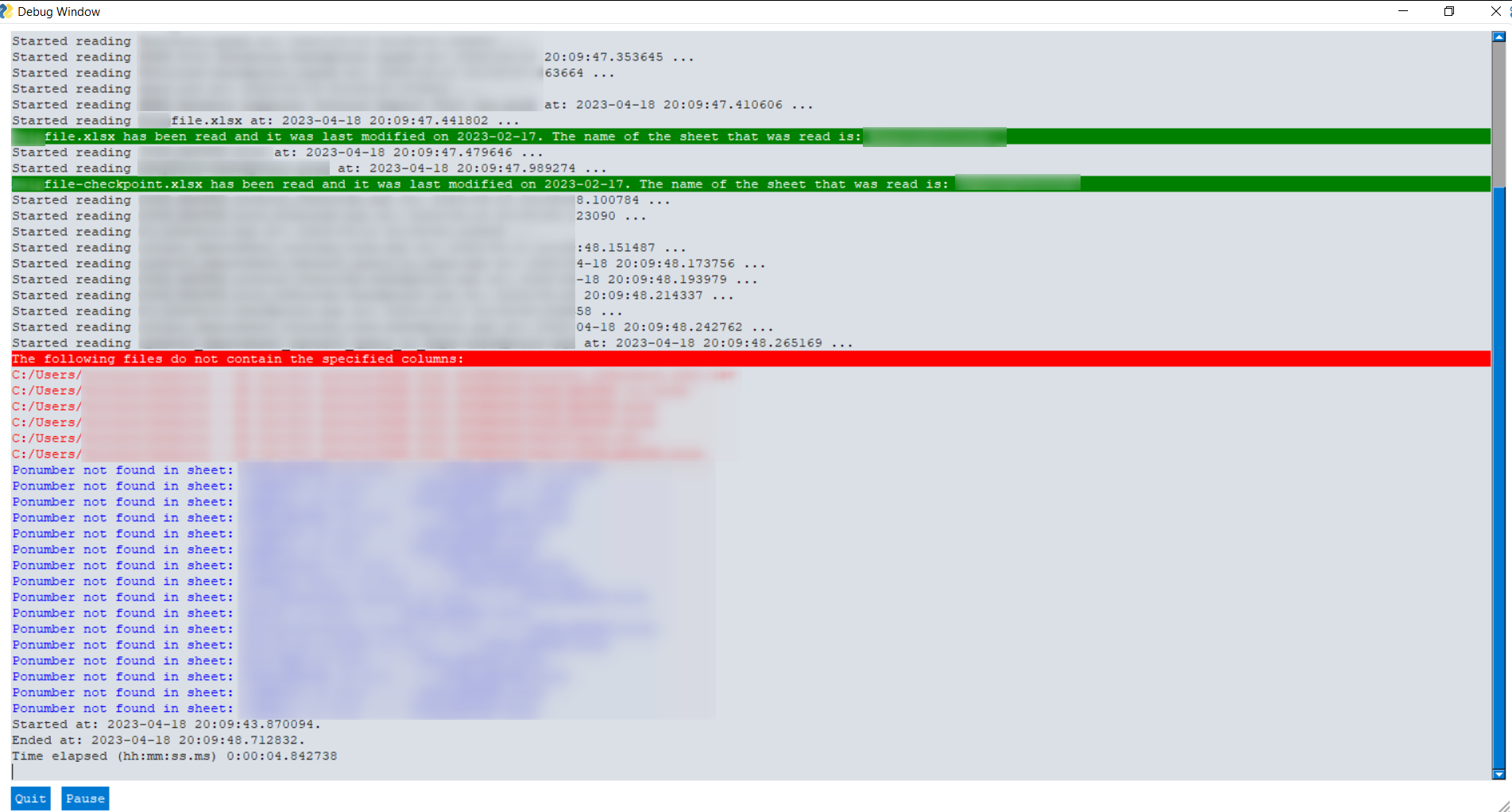
output - Shows colour coded log for which files were read in green and which were ignored in red background.
Screenshots¶
Some screenshots of the resulting app are as shown below:
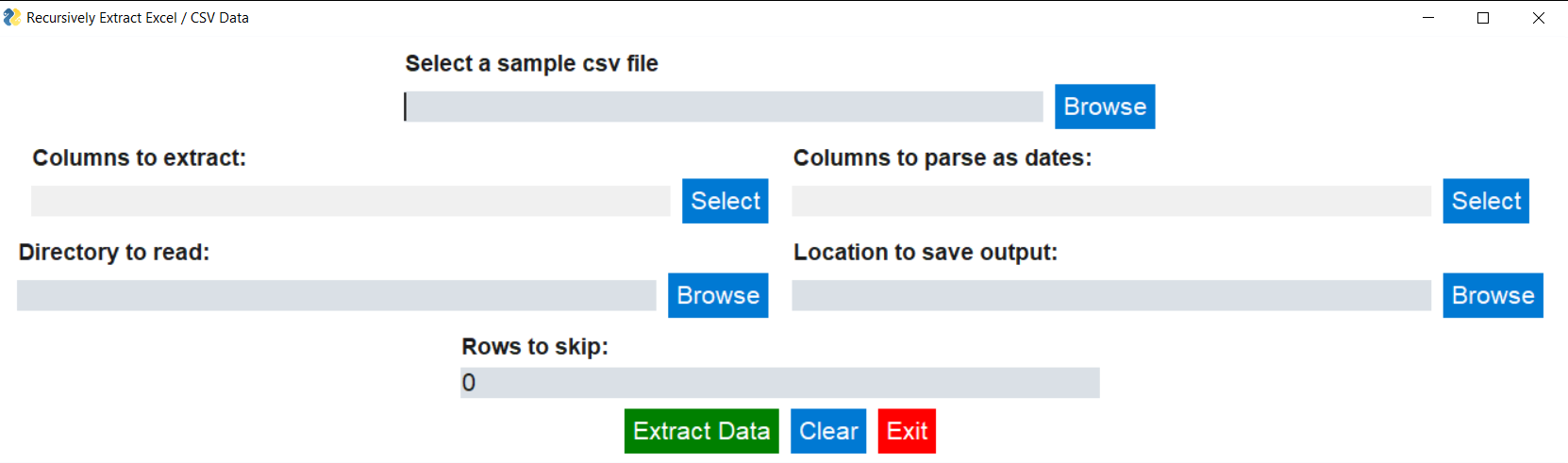
Empty Form¶
Filled Form¶
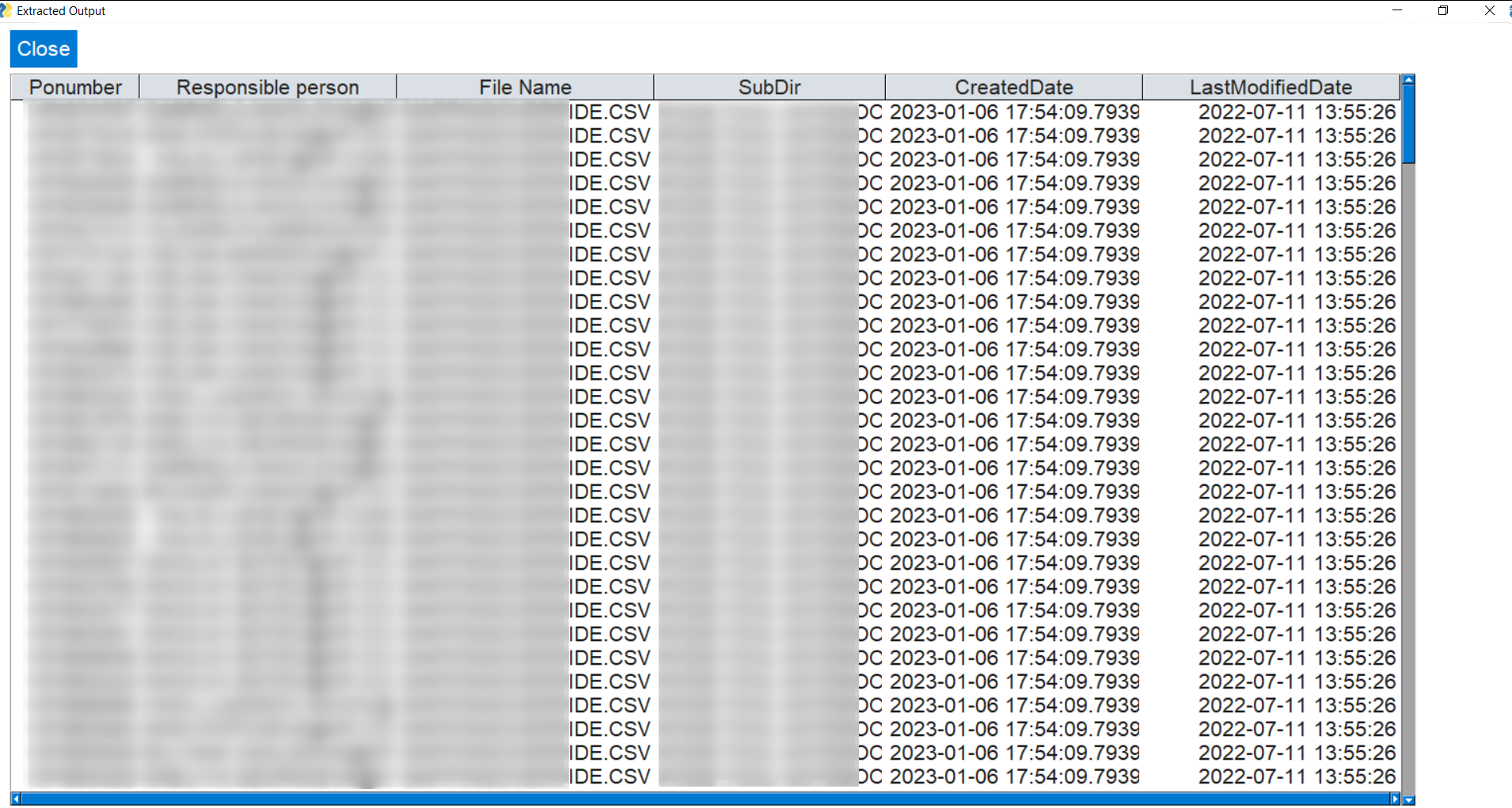
Displays extracted output¶
Displays filename of the output and location where it is saved¶
Colour coded log¶